April 28,2022 Post by : ชาญ อริยสัจจากุล
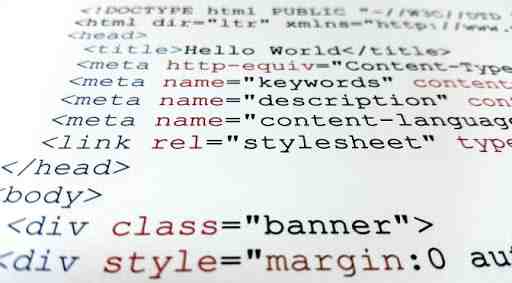
ภาษารวบรวมและตีความภาษาที่คอมไพล์คือภาษาที่โปรแกรมรวบรวมเมื่อแสดงในคำแนะนำของเครื่องเป้าหมาย ตัวอย่างเช่นการเพิ่ม "+" ในซอร์สโค้ดของคุณสามารถแปลโดยตรงไปยังคำสั่ง "ADD" ในรหัสเครื่อง

ภาษาที่ถูกตีความเป็นภาษาที่คำสั่งไม่ได้ดำเนินการโดยตรงโดยเครื่องเป้าหมาย แต่แทนที่จะอ่านและดำเนินการโดยโปรแกรมอื่น ๆ (ซึ่งโดยปกติจะเขียนด้วยภาษาของเครื่องดั้งเดิม) ตัวอย่างเช่นการดำเนินการ "+" เดียวกันจะได้รับการยอมรับโดยล่าม ณ รันไทม์ซึ่งจะเรียกฟังก์ชัน "add (a, b)" ของตัวเองพร้อมกับอาร์กิวเมนต์ที่เหมาะสมซึ่งจะดำเนินการคำสั่ง "ADD" ของรหัสเครื่อง .
คุณสามารถทำอะไรก็ได้ที่คุณสามารถทำได้ในภาษาที่ถูกตีความในภาษาที่คอมไพล์และในทางกลับกัน - ทั้งคู่นั้นทัวริงสมบูรณ์ ทั้งสองมีข้อดีและข้อเสียสำหรับการใช้งานและการใช้งาน
ฉันจะพูดคุยอย่างสมบูรณ์ (ปรมาจารย์ยกโทษให้ฉัน!) แต่โดยทั่ว ๆ ไปนี่คือข้อดีของภาษาที่รวบรวม:
• ประสิทธิภาพที่เร็วขึ้นโดยใช้รหัสเนทีฟของเครื่องเป้าหมายโดยตรง
• โอกาสที่จะใช้การเพิ่มประสิทธิภาพที่มีประสิทธิภาพมากในระหว่างขั้นตอนการคอมไพล์
และนี่คือข้อดีของภาษาที่ตีความ:
โปรดทราบว่าเทคนิคที่ทันสมัยเช่นการคอมไพล์ bytecode เพิ่มความซับซ้อนพิเศษ - สิ่งที่เกิดขึ้นที่นี่คือคอมไพเลอร์มีเป้าหมาย "เครื่องเสมือน" ซึ่งไม่เหมือนกับฮาร์ดแวร์พื้นฐาน คำแนะนำเครื่องเสมือนเหล่านี้สามารถรวบรวมได้อีกครั้งในภายหลังเพื่อรับรหัสเนทีฟ (เช่นที่ทำโดยคอมไพเลอร์ Java JVM JIT)